Publicação Eletrónica de um Livro
Publicação Eletrónica 2017/2018
Margarida Santos Silva
Mariana Gomes Oliveira de Castro
Sónia Marisa Ferreira Faria
| 2018-01-21 | |
Entrega do Projeto |
Palavras-chave:
XML , XSL , XSL Schema , Publicação Eletrónica, XSLT
O presente relatório visa reportar todas as fases da publicação eletrónica de um
livro, desde a análise do mesmo, com o intuito de perceber a sua estrutura, até à
construção propriamente dita da publicação em formato digital. Este projeto envolveu
o conhecimento e respetivo consolidamento das matérias abordadas na UC Publicação
Eletrónica, nomeadamente as linguagens XML, XML Schema e XSL.
Assim sendo, foi primeiramente criado o XML Schema para definir os elementos que
compõem o livro, bem como a sua relação hierárquica. Logo após criou-se a instância
XML, que consiste em preencher os campos definidos na fase anterior com blocos de
texto, imagens, entre outros. O passo seguinte consistiu em realizar duas
stylesheets para associar ao contéudo, anteriormente preenchido, o
formato pretendido, modificando o seu aspeto e dispondo-o no documento de modo
desejado. Com estas duas stylesheets gerou-se assim um documento HTML e um
documento PDF, que representam o objetivo final deste projeto.
1. Introdução
Com o impacto das novas tecnologias foram surgindo novas oportunidades, das quais
se pode destacar a publicação eletrónica. Esta surge assim como uma ferramenta
fundamental nos dias de hoje para armazenar informação e tratá-la, dando-lhe o
formato e aspeto desejável de forma eficiente. Noutros tempos esta tarefa seria mais
lenta e acarretaria erros ao longo do tratamento da informação.
Contudo, é necessário dominar algumas técnicas de modo a realizar a publicação
eletrónica, uma vez que o ato de publicar eletronicamente não conseguiste apenas em
digitalizar ou redigir um documento através de um computador. Trata-se sim de
estruturar o documento, recorrendo por exemplo a linguagens de anotação.
Assim sendo, surge no âmbito da UC Publicação Eletrónica o presente projeto, que
visa explorar e avaliar os conhecimentos obtidos durante as lições teóricas e
práticas acerca deste assunto.
É, portanto, pretendido neste trabalho prático a publicação eletrónica de um livro
publicado em papel, intitulado A "IMPRENSA" o que ela diz, sôbre o NAZI (Canário
Fadista) e o seu Canto.
De modo a orientar a execução deste projeto foram propostas várias etapas, sendo
estas as seguintes:
- Análise da informação fornecida;
- Planeamento da edição em papel (PDF) e da edição em HTML;
- Especificação de um XML Schema para a publicação final;
- Criação da instância XML;
- Criação da stylesheet XSLT para gerar a publicação HTML;
- Especificação/Planeamento do XSLFO para a geração do PDF;
- Especificação da stylesheet XSLT para a geração do XSLFO;
- Redação do relatório em XML (com transformação para HTML).
Estas etapas foram realizadas ao longo do projeto, sendo os resultados apresentados
nas secções seguintes.
2. Fundamentos Teóricos
O XML, abreviatura para
Extensible Markup Language, é uma linguagem de
anotação que permite armazenar dados num documento segundo uma estrutura
definida através de marcações (tag's). Esta linguaguem, uma vez que permite a
construção de documentos estruturados e que genéricos, facilita a troca de
informação entre sistemas diferentes, bem como o seu tratamento, permitindo
ainda que através de uma estrutura se criem vários ficheiros de modo eficiente.
Um documento XML e uma página web criada através do XML são formados por
anotações e dados, dados esses que na sua maioria serão blocos de texto.
[1]
O XML Schema é também uma linguagem, cujo resultado é um esquema que irá
definir a sintaxe do documento XML, abordado anteriormente. É nesse esquema que
se definem as anotações pretendidas, bem como a sua relação hierárquica,
formando assim a estrutura global pretendida. O esquema obtido não servirá
apenas como base na construção do documento XML, mas também para o validar.
[2]
Como alternativa ao XML Schema pode ser utilizado o DTD (Document Type
Definition), que, de modo análogo, descreve formalmente a sintaxe do
documento XML.
Uma vez que o XML Schema cuida apenas da estrutura do documento XML, é
necessário usar o XSL, abreviatura para Extensible Stylesheet Language,
que se encarrega de lidar com o aspecto, isto é, com a forma como os dados são
apresentados.
A necessidade da utilização do XSL surge do facto de as tag's criadas não
serem pré-definidas, tal como acontece no HTML, por isso não têm um estilo
associado logo à partida.
O XSL é constituido por várias partes, entre elas o XSLT e o XPATH. O XSLT é
uma linguagem cuja função é transformar documentos XML noutros documentos, por
exemplo documentos em formato HTML ou PDF. Por sua vez, o XPATH é uma linguagem
que permite a navegação através de documentos XML. O XSLT com recurso ao XPATH
vai permitir construir um documento cujos elementos nele contidos são dispostos,
ordenados, mostrados ou ocultados, segundo as 'templates' contidas nesse XSLT.
[3][4]
3. XML Schema
Para a realização da publicação eletrónica do livro supracitado foi primeiramente
necessário definir o seu XML Schema. Na construção do mesmo foi considerada a
estrutura original do livro impresso, definindo assim a estrutura genérica do
conteúdo deste.
Primeiramente considerou-se o livro dividido em 2 partes: capa e conteúdo, como se
pode visualizar na Figura 1.
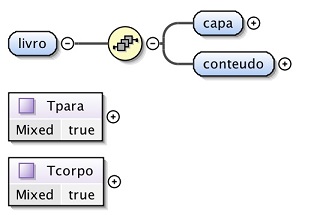
Figura 1: Subdivisão primária da estrutura do livro.
Para ajudar na construção de alguns elementos, que serão abordados posteriormente
neste relatório, criaram-se Complex Types de modo a não repetir a construção
das mesmas subestruturas de elementos penduradas em elementos diferentes. Este tipo
de estrutura pode assim ser chamada várias vezes na estrutura principal
anteriormente criada para atribuir ao elemento em que se encontra pendurada as
caracteristicas nela contidas. Assim sendo, criaram-se o Tpara e
Tcorpo que são exemplos dessas estruturas, estando representadas na
Figura 1, anteriormente mostrada, e que representam a estrutura do
parágrafo e a do corpo, respetivamente.
A capa é constituida por uma sequência de três elementos: o título, a
imagem e a data. Em que o título e a data são do tipo
string, isto é, são blocos de texto, enquanto que a imagem tem na sua
constituição um atributo designado path que servirá para invocar a imagem
apartir do caminho onde esta se encontra. É possível visualizar a estrutura
idealizada na Figura 2.
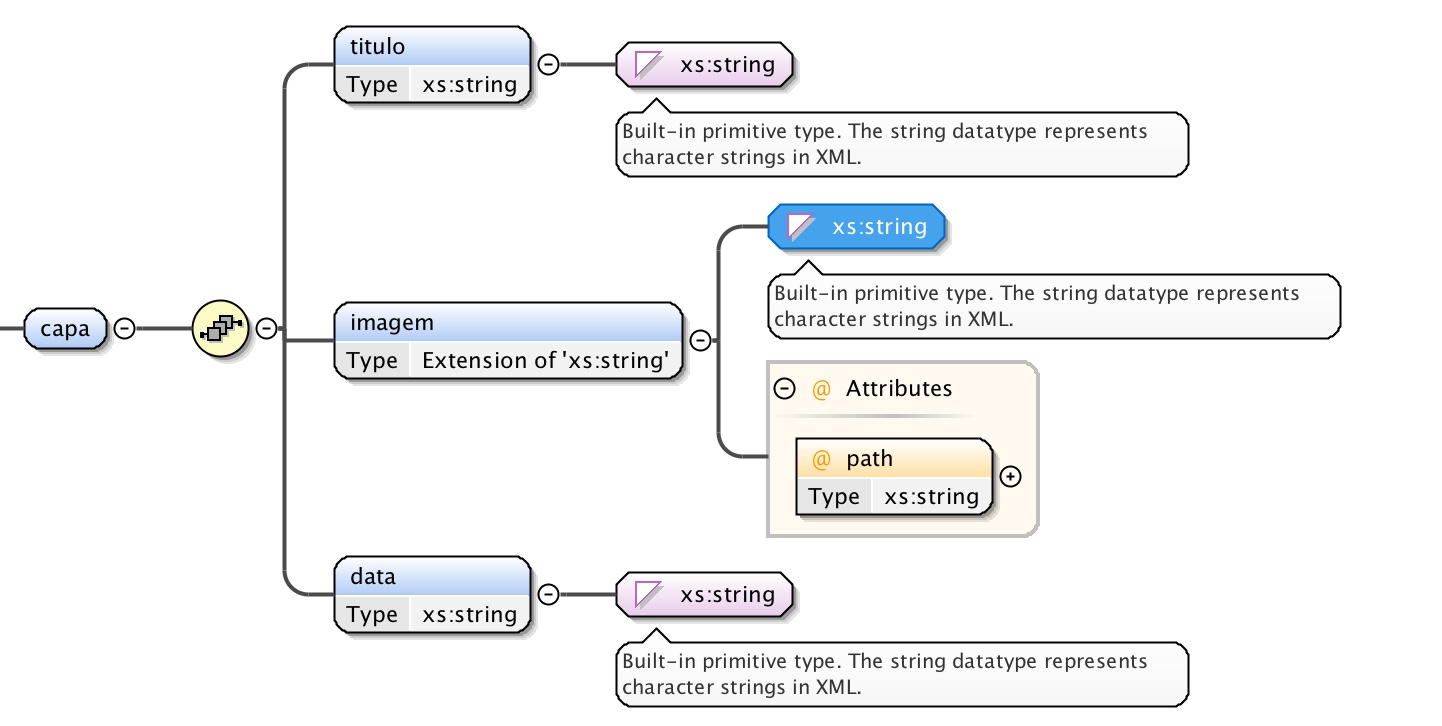
Figura 2: Elementos estruturantes da capa.
Por sua vez, o contéudo é constituido por uma choice entre dois tipos de
recorte apresentados, podendo estes ser uma notícia ou uma canção.
A Figura 3 representa a estrutura referida.
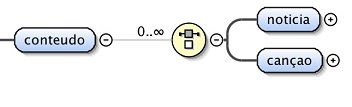
Figura 3: Elementos estruturantes do conteúdo.
Quanto à noticia, considerou-se esta como uma sequência dos elementos
meta e corpo, em que o primeiro consiste no cabeçalho do
recorte, contendo como subelementos o título do jornal, a data da
publicação e a cidade, sendo que estes subelementos são todos de formato
string
Nesta situação recorre-se ao Complex Type
Tcorpo para definir o corpo, sendo que a estrutura definida no primeiro é
então utilizada para definir a estrutura do último.
É possível visualizar a estrutura da notícia na Figura 4, abaixo
apresentada.
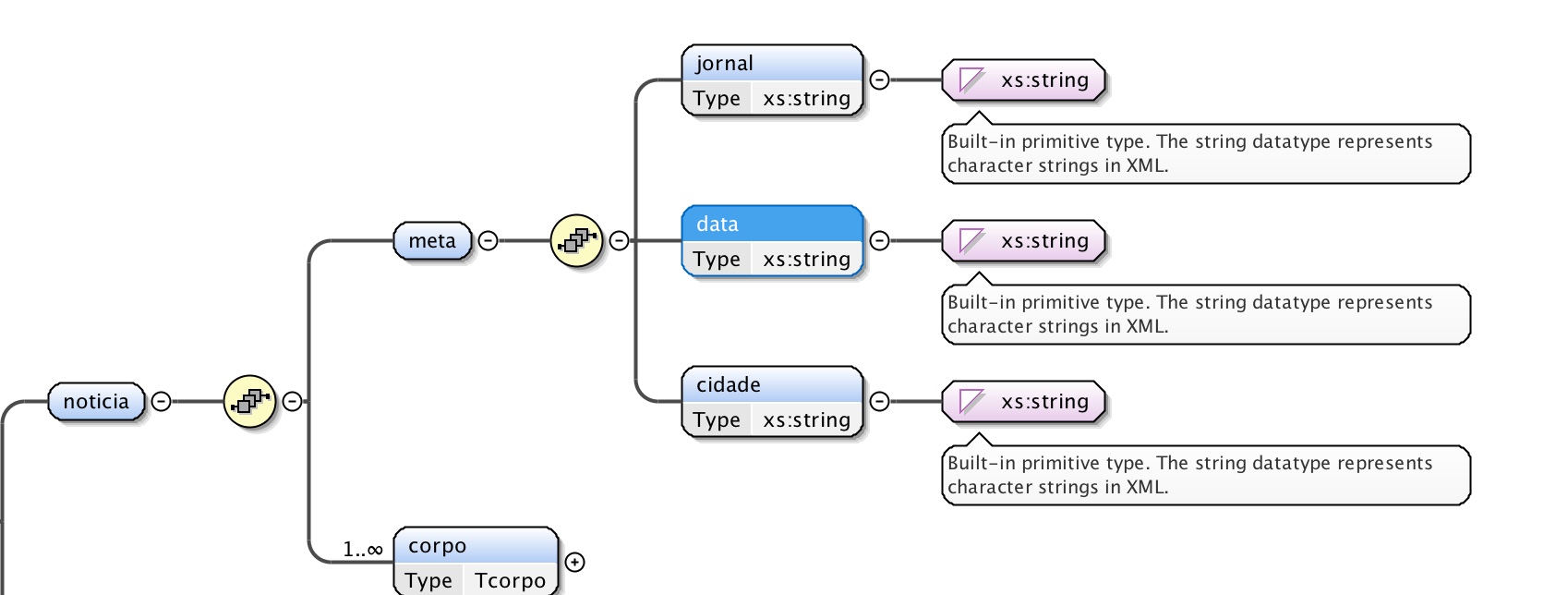
Figura 4: Estrutura da notícia.
A estrutura da canção assemelha-se em tudo à da notícia, com exceção na
construção do meta, uma vez que neste caso este elemento apenas é
constítuido por uma sequência de título e autor, ambos campos
string. Esta estrutura verifica-se na Figura 5.
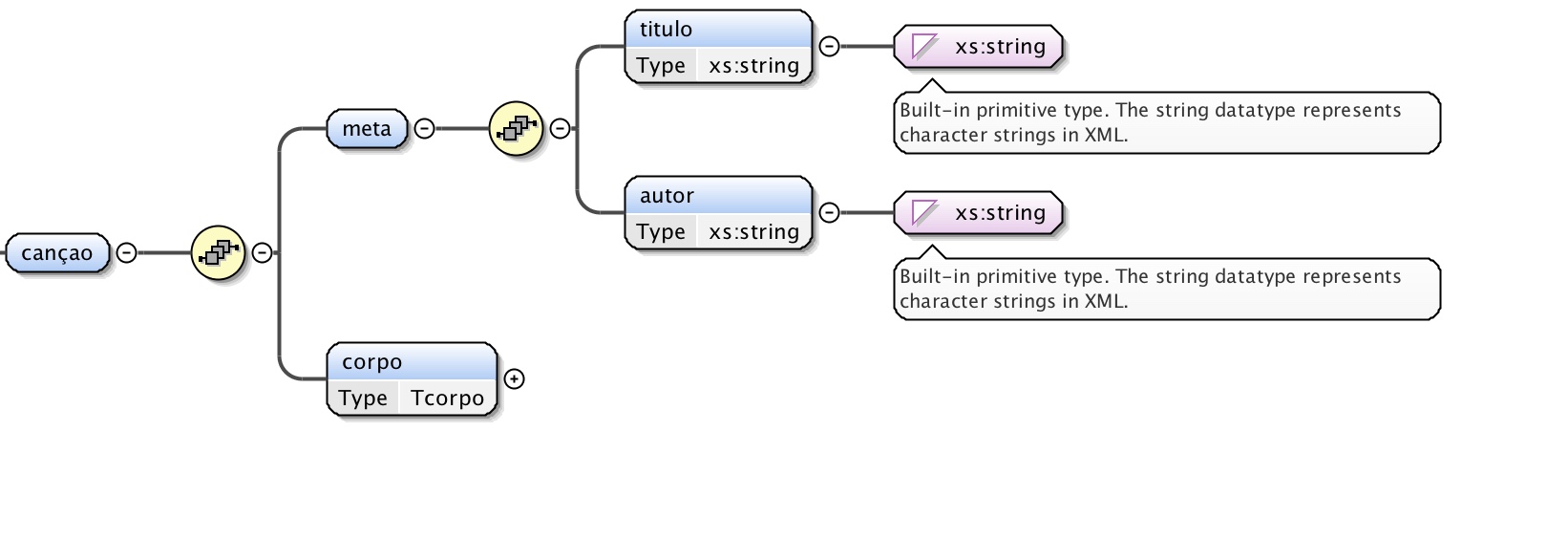
Figura 5: Estrutura da canção.
3.3. Estrutura complexa Tcorpo
Como referido anteriormente, criou-se o Complex Type
Tcorpo cuja função é auxiliar a construção de elementos que tenham a
mesma estrutura, mas que estejam em locais diferentes do esquema global,
permitindo assim a não repetição de código ao longo da construção do mesmo.
Assim sendo, esta estrutura foi utilizada na estrutura respeitante ao
corpo, quer na noticia, quer na canção.
O Tcorpo é definido assim como sendo uma sequência de título e
subtítulo campos de texto opcionais, seguidos da subestrutura
informação e da imagem, que em tudo se assemelha com a já referida na
Secção 3.1.
A subestrutura informação é, por sua vez, uma escolha (choice)
que pode ser realizada infinitas vezes, entre os elementos estrofe,
parágrafo e autor. O primeiro elemento é uma sequência de 1 ou
mais versos que assumem as propriedades de um parágrafo definidas no
Complex Type
Tpara. Já o segunto elemento é também ele, tal como o verso do
tipo Tpara. Enquanto que o último elemento é de texto.
É possível visualizar a estrutura referida na Figura 6, apresentada logo
de seguida.
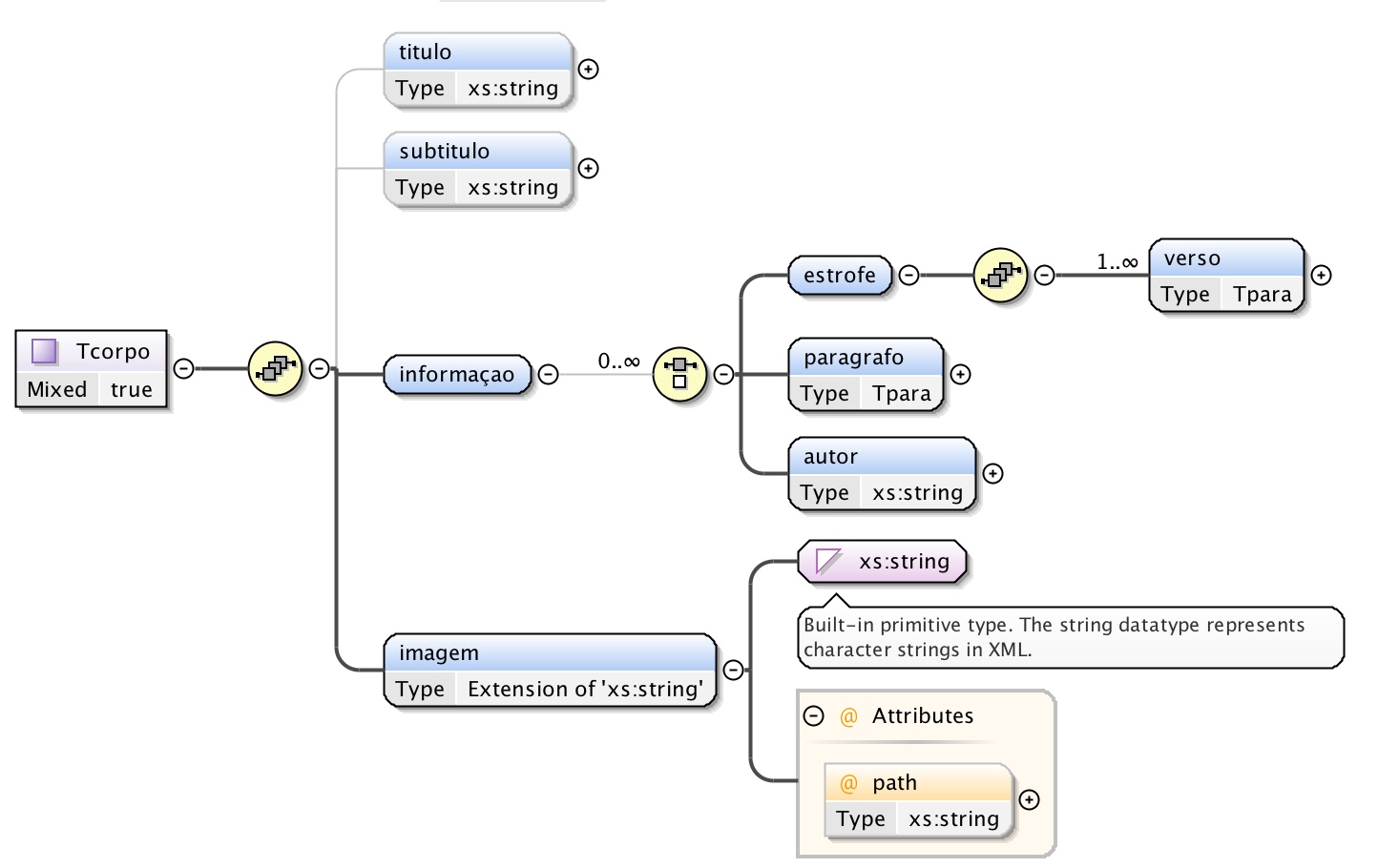
Figura 6: Estrutura complexa designada Tcorpo.
3.4. Estrutura complexa Tpara
Do mesmo modo criou-se o Complex Type
Tpara utilizado como estrutura dos seguintes elementos: parágrafo
e verso.
Esta estrutura é definida recorrendo a uma choice, que pode ser
realizada infinitas vezes, entre os elementos b, i,
lugar, nome, data e
indicação, representados na Figura 7. Os quatro últimos
elementos são de formato string, enquanto que os quatro primeiros
representam subestruturas, abordadas já de seguida.
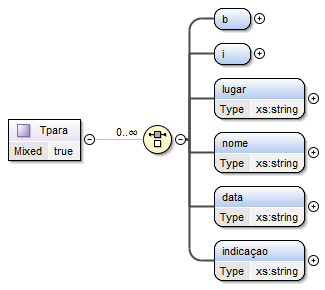
Figura 7: Estrutura complexa designada Tpara.
As subestruturas b e i, representadas na Figura 8, são
similares, uma vez que são constituídas por uma sequência em que podem ser
escolhidas múltiplas vezes o elemento i ou b (respetivamente)
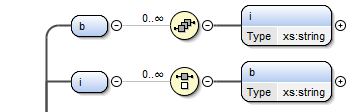
Figura 8: Parte da estrutura complexa designada Tpara.
4. Stylesheet para geração de HTML
Com o objetivo de gerar a publicação HTML, mais precisamente um website, a partir
do documento XML, foi criada a stylesheet XSLT. De forma a dar um aspeto
diferente às páginas web, recorreu-se à utilização do "style" e às
formatações oferecidas pelo "w3css".
Primeiramente foi criado um "xsl:result-document" que engloba o conteúdo para uma
determinada página web. O URL da página é especificado a cada "xsl:result-document".
Neste caso, a primeira página corresponde à capa,composta pelo título, pela data e
pela imagem presente na subcapa do documento digitalizado. De seguida é apresentado
parte do código correspondente à estruturação da capa.

Figura 9: Excerto do código relativo à elaboração da capa.
Num segundo momento, gerou-se outro "xsl:result-document" correspondente ao índice.
Este é dividido em "Notícias" e "Canção", onde cada uma destas divisões engloba os
links dos respetivos artigos, os quais irão redirecionar para a página de cada um
destes artigos em questão.
No fim de cada página encontra-se uma barra de navegação, que permite ir para a
capa ou para as páginas dos artigos, no caso de nos encontrarmos no índice, ou
permite navegar pelos diferentes artigos e voltar ao índice, caso nos encontremos
já
numa página relativa a um artigo. De seguida é possível observar um excerto do
código relativo à construção do índice.

Figura 10: Excerto do código referente ao índice.
De seguida, aplicou-se um "apply-templates" para o conteúdo do documento, o qual
compreende as notícias e a canção, com o intuito de, subsequentemente, se determinar
a formatação para cada um destes elementos.
Neste seguimento, foram criados dois templates, um para as notícias e
outro para a canção. Cada um destes templates inclui um
"xsl:result-document" de forma a que cada artigo apenas se encontre numa única
página web (com um único URL) a ele destinada. De seguida é apenas apresentado o
código correspondente a cada notícia, uma vez que a canção é estruturada de forma
semelhante.

Figura 11: Código respetivo à estruturação da página web de uma notícia.
Uma vez que o corpo de um artigo de notícia é semelhante ao de uma canção, apenas
se gerou um templates geral para o "corpo". Este é constituído por uma
tabela de duas células, onde a primeira é incorporada pela imagem do artigo e a
segunda integra o texto presente na imagem e, caso existam, o título e subtítulo
correspondente. É ilustrado de seguida o código correspondente a este
templates.

Figura 12: Código relativo à estruturação do corpo de cada artigo.
Por fim, foram criados os templates para a informação, imagens,
parágrafos, estrofes, versos, entre outros, com o objetivo de dar forma a esse conteúdo.
5. Stylesheet para geração de PDF
De modo a converter o documento XML em PDF, foi especificada a stylesheet
XSLT para a geração do XSLFO.
Inicialmente, definiu-se que a primeira página deste documento iria corresponder à
capa, composta pelo título do livro, a imagem que estava na subcapa do livro
digitalizado e a data. A segunda página diria respeito ao índice, e cada página das
restantes iria compreender cada artigo do livro.
Desta forma, procedeu-se ao desenvolvimento da stylesheet. É possível
observar a sua parte inicial na figura a seguir apresentada.

Figura 13: Excerto de códifo relativo à estruturação das páginas do PDF.
Como se pode verificar, foram especificadas as formatações da capa e do índice, e
aplicado um "apply-templates" para, posteriormente, se especificar a formatação do
conteúdo. O elemento "fo:page-sequence" permite iniciar uma nova página e indicar
o
que se pretende em cada uma. Recorrendo ao elemento "fo:block", são criadas áreas
retangulares que englobam um certo conteúdo no seu interior.
Note-se que ao longo da construção do documento, foram definidos vários elementos
que permitem dar o aspeto pretendido às páginas, como por exemplo aplicar
espaçamentos, mudar o tipo e o tamanho da letra, alterar o tamanho de imagens, etc.
Na figura apresentada de seguida, é possível verificar como foi gerado o índice,
dividido em "notícias" e "canção", visto que o livro tem várias notícias e uma
canção no final.

Figura 14: Estruturação do índice.
Como se pode constatar, é gerado um id para cada notícia e para cada canção,
para apresentar a página de cada um e para criar um link de maneira a ser
possível ir diretamente para o artigo desejado. Desta maneira, na lista de conteúdos
aparece o nome do jornal e a data de cada notícia, o título da canção, e o respetivo
número de página.
De seguida, criou-se o template da notícia, apresentado na figura abaixo.
Note-se que foi também criado de maneira análoga o template da canção, pelo que não
vai ser aqui exibido.

Figura 15: Estruturação da notícia.
Seguidamente foi especificado o template do "corpo" (que pertence tanto às
notícias como à canção), demonstrado na figura seguinte.

Figura 16: Estruturação do corpo das notícias e da canção.
Cada corpo é composto por uma tabela com uma linha, sendo que esta tem uma célula
à
esquerda com o recorte da notícia/canção e uma célula à direita com a transcrição
do
texto da imagem.
Subsequentemente, foram elaborados os restantes templates, nomeadamente para as
imagens do "corpo", informação, estrofe, parágrafo, verso, etc.
6. Conclusão
Com a realização deste projeto assimilaram-se e aprofundaram-se os conhecimentos
sobre as linguagens nele usadas, nomeadamente o XML, o XML Schema e o XSL.
Através deste projeto foi possível compreender o papel que a publicação eletrónica
desempenha nos dias de hoje, sendo que esta agiliza o processo de publicação em
formato digital e sem ela este seria muito mais demorado e não seria de modo algum
automático.
Os objetivos inicialmente planeados foram cumpridos, obtendo assim como resultado
a
publicação em formato HTML e em formato PDF, obtida através das stylesheets
construidas para o efeito.
Em suma, o trabalho realizado poderá servir, num futuro próximo, de exemplo para a
realização de outras publicações inseridas, por exemplo, em contexto académico.
| [1] |
ROSS,Timothy. XML - Managing Data Exchange. 2007. |
| [2] |
BIRON, Paul V., et al. XML schema part 2: Datatypes. 2004. |
| [3] |
XSL(T) Languages. Acedido em 12/11/2018 através de
https://www.w3schools.com/xml/xsl_languages.asp.
|
| [4] |
CLARK, James. XSL Transformations (XSLT). W3C Recommendation 16 November.
1999.
|