3. Resultados obtidos
Com a elaboração deste trabalho prático pretendia-se a exploração do conteúdo de notícias
antigas a fim de elaborar uma forma mais
recente e moderna de representar os dados que nela continham, sem descartar a
forma inicial. Para que isto fosse possível foi necessário recorrer a duas formas
de representação
de informação, sob a forma de duas extensões, HTML e PDF. Para tal, foi necessário
elaborar quatro ficheiros distintos para obter os resultados pretendidos. A fim de
se atingir os resultados seguiu-se um conjunto de procedimentos
que, encadeados entre si, permitem atingir um fim.
Os ficheiros elaborados para que fosse possível atingir o resultado pretendido foram
os seguintes:
Schema, Documento XML, Stylesheet para geração de HTML e Stylesheet
para geração de PDF.
3.1. Schema utilizado
A elaboração de um Schema tem como principal objetivo delimitar a estrutura da informação
que se pretende representar. Para tal, é necessário estudar a informação que se pretende
representar e determinar quais as suas partes fulcrais. Assim, foi necessário identificar
todas as estruturas de texto e a forma como se pretende que estas sejam apresentadas
para que, depois, seja possível a partir destas informações elaborar o ficheiro XML
com os respetivos conteúdos. Assim, resolveu-se criar a estrutura que é apresentada
na imagem seguinte.

Através da análise da imagem anterior é possível retirar algumas conclusões quanto
à representação do conhecimento que se pretende abranger. Estas conclusões são as
apresentadas de seguida:
- A raiz do documento é constituída pelas informações principais do documento, sobretudo data, titulo, e, tambem por um elemento Capitulos.
- O elemento Capitulos e uma sequencia de 1 ou mais elementos Capitulo, represtando este cada um dos recortes disponíveis.
- Cada capítulo é uma sequência de informação relevante, tal como o nome do autor, a data, o local, entre outros.
- Cada Capitulo apresenta tambem um elemento corpo que é uma escolha de 1 o mais elementos dentro de uma lista com os elementos Poema, Notícia, Música.
- Estes, por sua vez, foram estruturados tendo em conta sua estrutura e como se representa a informação em cada uma das formas anteriores.
De realçar a elaboração de uma variável global do tipo complexo de dados, para que
fosse possível elaborar uma forma de representação do texto comum a todos os elementos,
tornando assim mais fácil de identificar elementos como nomes, locais entre outros.
3.2. Stylesheet para geração do documento HTML
A fim de se elaborar um ficheiro HTML com os dados que estão representados no documento
XML elaborado anteriormente, criaram-se um conjunto de templates para que fosse possível
retornar as informações que pretendíamos de uma forma estruturada e de acordo com
o que se pretendia.
Na abordagem elaborada pelos nossos elementos do grupo, decidiu-se que cada notícia
seria isolada numa página distinta, e que estas seriam interligadas através de uma
página inicial.
Começou-se por se criar uma template para a raiz do documento que permite a criação
do documento index.html que serve de página inicial e de índice. Nesta página podem
encontrar-se dados como a data, a decrição e informações que foram anteriormente atribuídas
ao projeto, bem como informações dos elaboradores do projeto e da Unidade Curricular
para o qual foi desenvolvido.
Nesta template, deve realçar-se o facto de o índice ser elaborado através de um
apply templates, contrariamente aos outros, em que se vai buscar diretamente os dados
pretendidos.
O apply templates referido, aplica a template capitulos, que permite a criação desse
mesmo indice, pondo em header "Índice de Notícias" e dentro de um parágrafo o índice
realiza um novo apply templates, desta vez da template capitulo, que vai gerar um
botão para cada uma das páginas.
A página inicial ficou então com o seguinte aspeto:

Após elaborada a página incial é então necessário proceder à elaboração das páginas
individuais. Para tal criou-se uma nova template capitulo, no entanto atribuiu-se
desta vez um mode contents, que restringe as templates aplicadas. Esta template vai
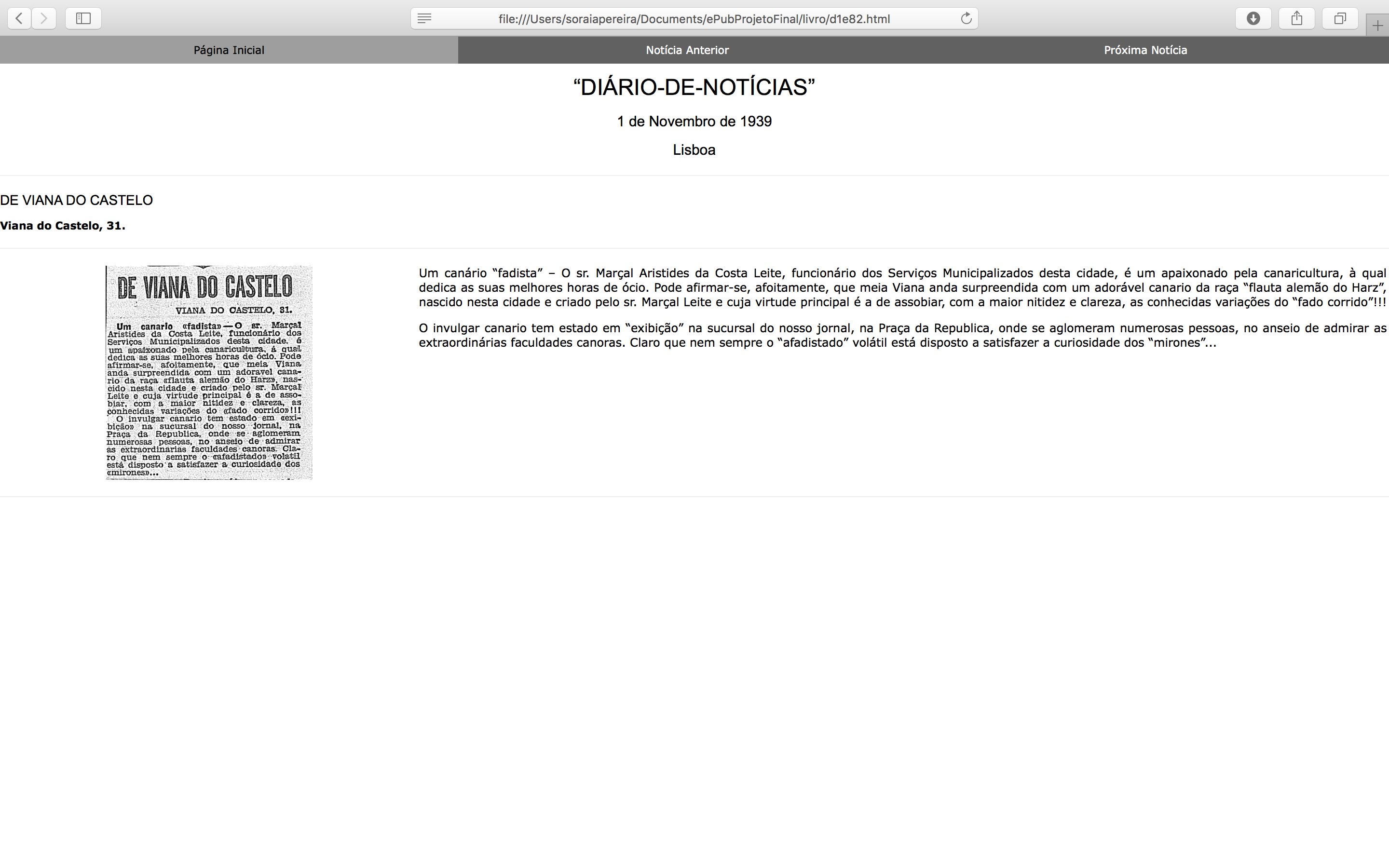
gerar uma página HTML para cada um dos recortes,
sendo que cada uma dessas páginas é constituída por uma barra de navegação que
permite aceder à notícia que se apresenta imediatamente a seguir, e a que se apresenta
imediatamente antes, caso estas existam, ou à página principal. Nesta colocaram-se
também as imformações relevantes de cada recorte, tal como autor, data entre outros
e aplicou-se de seguida as templates necessárias para transcrever os recortes.
Para esta transcrição foi necessário elaborar novas templates, poema, musica e noticia,
que acentam nos mesmos ideais. Esta template divide a página através de uma tabela
e coloca de um lado a foto do recorte que estamos a estudar e do outro a sua transcrição.
Nestas templates foi necessário aplicar outras templates, tais como:
- Template Parágrafo: permite inserir o valor do elemento paragrafo numa tag paragrafo do html;
- Template Falas: cria uma lista em que os elementos serão as falas, que se encontram em itálico.
- Template Quadra,Musica e estrofe: insere algo num bloco parágrafo.
- Template Estrofe/Verso: transforma o conteúdo para itálico e insere-o num parágrafo.
- Template Refrao/Verso: transforma o conteúdo poara bold e insere-o num parágrafo.
- Template verso:realiza o mesmo que a Template Estrofe/Verso.
Assim, cada uma das página geradas ficou com uma estrutura semelhante à apresentada
de seguida.
3.3. Stylesheet para geração do documento PDF
Começou-se por criar uma stylesheet para gerar o documento PDF.
Passemos então à explicação das diversas templates contidas na stylesheet:
- A template para a raiz vai definir as páginas (ou seja, como elas são), e de seguida vai chamar essa página para criar a capa, na qual vai ser colocado o título, os elementos do grupo e um 'rodapé'. Na mesma template será criado o índice, invocando outra sequência de paginas. Neste serão inseridas diversas linhas correspondentes a cada notícia, diferenciadas pelo autor e data e inclui o numero da pagina em que se encontram. Por fim é feito um "apply templates" para poder ser inserido conteúdo;
- Na template conteúdo é criado um conjunto de páginas para cada notícia, sendo que nestas páginas existe um rodapé com o número da página e o conteúdo consiste na identificação do autor, data e local e de seguida as notícias/poemas/músicas correspondentes (tratados por templates diferentes). No fim existe também um apply templates;
- As templates do Poema, da música e da notícia são iguais, definem uma tabela em que na primeira célula insere o conteúdo e na segunda a imagem. É então criada a tabela e na primeira existe um apply templates para as restantes templates tratarem o conteúdo, e na segunda temos o import da imagem com o fo:external-graphic;
- A template do parágrafo insere o seu valor dentro de um bloco fo;
- A template das falas cria uma lista em que que o elemento é uma fala;
- A template das estrofes cria um bloco fo em que o seu conteúdo é um apply templates, o mesmo para a quadra;
- Por fim, a template do verso da quadra transforma o valor deste em itálico e insere dentro de um bloco, o mesmo acontece no verso da estrofe, com a exceção de este não ser em itálico e o do refrão encontra-se em bold.